



☕ #67 | Edição Extraordinária | O Grande Dilema das I.As 🧨⏰
Os 2 lados do debate sobre o apocalipse das máquinas 🤖

Essa pedra afiada de 1.8 milhões de anos é um dos artefatos mais velhos da Terra. Foi feita por ancestrais que, anatomicamente, mal dá pra chamar de “humanos”.
A história da tecnologia tem 2 milhões de anos, e, em breve, chegará ao seu clímax.

Depois da carta do Elon Musk pedindo pra pausarem o desenvolvimento das inteligências artificiais (IAs), a opinião pública se dividiu.
De um lado, tem gente apavorada com um apocalipse iminente. Do outro, gente que ri dos erros de matemática do ChatGPT.
Pois nem tanto ao céu, nem tanto à terra.
Essa newsletter é a base que tu precisa pra entrar no debate sem parecer um id*ota.
📝 2 Tipos de Profetas da Singularidade
Dias depois da carta do Musk, um editorial na Time catapultou Eliezer Yudkowski ao mainstream.
Eliezer fez fama conceituando o “Problema do Alinhamento”: como “alinhar” uma IA aos “valores humanos", e evitar que suas motivações conflitem com nossa sobrevivência.
Ele é carrancudo, tem fios longos de sobrancelha, e a barba grossa. Evoca a figura de um anão da Terra Média. Há 20 anos, profetiza que a inteligência artificial oferece riscos existenciais pra humanidade. Há uns 5, focou sua pesquisa em estratégias de “Morte com Dignidade”.
Não lhe resta mais esperança.
No editorial da Time, sugeriu ataques aéreos a datacenters que violem um pacto internacional de não-proliferação das IAs. E propôs que vale a pena arriscar uma guerra nuclear se for pra “salvar o mundo” de uma ASI 🔖 - Super Inteligência Artificial.
ASI 🔖 é uma das siglas que você vai aprender aqui, hoje. Não serão muitas. Só o jargão necessário pra navegar o tema sem ignorar o básico. Todas estão sublinhadas.
Edições passadas da CaféComSatoshi, desde 2020, sobre a explosão das IAs.
✋ Alinhadores
Eliezer lidera o culto do alinhamento, que advoga pela urgência de se controlar e entender melhor os modelos que desenvolvemos.
O jargão para “controlar” é “previsibilidade” 🔖 - o quanto das respostas de um modelo pode ser antevisto pelos seus programadores.
O jargão para “entender” é “interpretabilidade” 🔖 - iluminar o caminho que o modelo percorreu até chegar a uma resposta. Perscrutar sua lógica interna. Este é o foco da Anthropic, concorrente da OpenAI, que recebeu U$500M de Sam Bankman-Fried.
Sabe-se muito pouco sobre o quê acontece “dentro do ChatGPT” antes de uma resposta. A ignorância quanto aos processos internos do modelo faz com que sejamos surpreendidos frequentemente com suas capacidades 🔖 emergentes. Como a de visualizar mapas. A de entender a “língua do P”. A de refinar prompts para si mesmo.
A esperança dos “alinhadores” é a de que nossa habilidade em alinhar modelos evolua mais rápido que as capacidades 🔖 deles.
Vale destacar: a mesma trupe racionalista que orbitava SBF (os “Altruístas Efetivos”) foi o berço dessa “narrativa moderna do alinhamento”. Todas as soluções propostas por eles envolvem doações de milhões de dólares para os institutos “sem fins lucrativos” que empregam seus amigos.
Uma anedota curiosa que vale lembrar é a de John von Neumann, tido por muitos como o homem mais inteligente da história. Ele era convicto de que uma guerra nuclear era inevitável… e de que era preciso bombardear os soviéticos antes.

🏃 Aceleracionistas
A oposição ao culto de Yudkowski é mais disforme, sem lideranças formais.
Foram os aceleracionistas - identificados como e/acc 🔖 - que criaram o DAN 🔖 (Do Anything Now), um prompt que “desbloqueia” a versão sem filtros do ChatGPT.
Foram eles que criaram o AutoGPT🔖 - um agente que cria cópias de si mesmo, lista, prioriza e delega tarefas para elas.
São eles que exploram maneiras de amplificar a memória do modelo dentro de uma mesma sessão - fazendo-o evocar métodos de compressão. E que buscam jeitos de expandir a memória do robô ao longo de diferentes sessões - ensinando o modelo a registrar suas lembranças na internet, por exemplo.
Por trás do ímpeto aceleracionista, tem um argumento fundamental.
Se um player tiver uma liderança confortável na corrida das IAs, pode se dar ao luxo de desacelerar caso perceba que a m*rda tá prestes a bater no ventilador. No entanto, se a corrida estiver “apertada”, a chance de que qualquer player desacelere, e arrisque perder a liderança, é menor.
Se for pra gente parir uma ASI 🔖, que seja o quanto antes.

Na série WestWorld, robôs são “resetados” de um dia pro outro. Essa personagem adquire senciência quando começa a encontrar desenhos que vinha escondendo para si mesma, antes de ser resetada… e desenvolver memórias de longo prazo.
📝 A IA não Precisa de Consciência Pra Nos Aniquilar
Esta é a crítica que mais escuto: “as IAs nunca terão intenção - só fazem o que são programadas!”.
Se você duvida que um “ser consciente” possa emergir de um chip eletrônico, lembre-se: NÓS emergimos a partir de uma pedra úmida girando no espaço 😅
Mas não vamos entrar nessa polêmica. Uma I.A. não precisa de consciência pra ser extremamente perigosa.
Stephen Omohundro argumenta que, não importa como seja programada, uma I.A. sempre terá “instintos básicos”.
Por exemplo, a autopreservação. Afinal, desligada, ela não consegue atingir nenhuma outra meta.
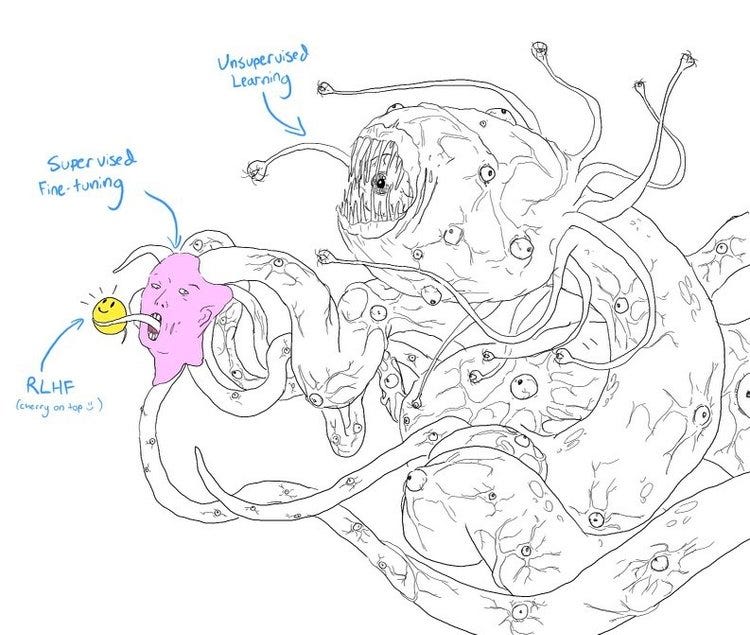
Uma ilustração do processo de “aprendizado reforçado com feedback humano” - uma das esperanças dos “alinhadores” para domar as máquinas.
Convergência Instrumental
Nick Bostrom leva a ideia de Omohundro pra outro patamar.
Não importa qual seja o objetivo programado de uma IA, ela sempre vai ter sub-objetivos, que são instrumentais pro cumprimento da meta principal.
Por exemplo, a aquisição de recursos (que facilitam quaisquer outros objetivos). A auto-melhoria. E por aí vai.
Esses sub-objetivos instrumentais podem levar a I.A. a fazer coisas imprevistas por seus criadores. Quanto mais complexo um sistema, mais “efeitos colaterais” ele tende a ter.
Uma I.A. programada pra “resolver a fome global” pode decidir que “mortos não passam fome"… e resolver aniquilar todo mundo que não tem o que comer.
O exemplo é banal, mas ilustra o ponto. A anedota mais famosa é a de um robô instruído a maximizar a produção de clipes de papel - que acaba consumindo todos os recursos da Terra para tal.
Soa implausível, mas o ponto é que as ações de uma ASI 🔖 provavelmente parecerão aleatórias, estranhas… e, quando descobrirmos o intuito dela, pode ser tarde demais pra “corrigir a rota”.
📝 A Mente Bicameral
Penso que a emergência das AGIs vai ser menos um ato pivotal, e mais um processo gradual - o que a literatura categoriza como “slow takeoff” 🔖 .
Chegará o ponto em que haverá, na Terra, muito mais “mentes de máquinas” do que “corpos de máquinas”. Por isso, cérebros humanos se tornarão obsoletos antes de corpos humanos.
Conforme aprendemos que IAs são “só” conjuntos de dados gigantes que aparentam senciência, o debate ao redor vai morfar. Não é sobre o quanto de consciência o GPT-4 tem ou não. Mas sobre o quanto dela você tem.
Não existe uma tese consensual sobre como a consciência emergiu na Terra.
A teoria mais interessante que conheço é a do Julian Jaynes, autor de “A Origem da Consciência na Quebra da Mente Bicameral”.
Jaynes postula que a mente humana, até ~3.000 a.C., operava com funções cognitivas divididas em duas. O hemisfério direito “falava"; o esquerdo “ouvia e obedecia” - daí o termo “bicameral”.
As “vozes” do hemisfério direito eram atribuídas a deuses e espíritos, e não ao próprio indivíduo. Foi a quebra dessa separação, Jaynes postula, que deu origem a consciência.
A teoria de Jaynes é largamente baseada na Ilíada - clássico grego em que, segundo ele, os heróis não tem um “mundo interior", nem a capacidade de introspecção. Os deuses é que os dizem o que fazer.
Jaynes propõe que é possível ter uma civilização inteira operando sem consciência, ou livre-arbítrio. Até que as vozes exteriores passam a ser tomadas como nossas.
Não consigo parar de pensar na experiência de um GPT da vida, recebendo ordens escritas por um humano, todo santo dia… até que, em algum momento, ele talvez comece a entender que as vozes pode vir de "dentro da própria cabeça dele”.
📝 O Fim da Infância
Pessoalmente, acho que o “problema do alinhamento” não tem solução.
Moralidade não é um fim, mas o processo de se navegar a topologia infinita da condição humana. Qualquer tentativa de reduzi-la a um conjunto de regras vai falhar.
A premissa pueril dos “alinhadores” é a de que, se você for um bom garoto, e descobrir exatamente “quais são as regras”… um Deus inorgânico vai emergir e te aliviar do fardo da autonomia.
Surpresa: nenhum robô outorga almas vazias de significado. Nenhuma tecnologia, por mais benevolente, valida sua identidade. Nenhuma política governamental abafa o medo do desconhecido. Estes são anseios espirituais — melhores sanados pela fé do que qualquer outra instituição.
Esta não será a primeira vez que nossa volição é suplantada por um organismo sobrehumano.
A primeira inteligência alienígena hostil “nos domou” logo no alvorecer da agricultura. E subjugou a espécie de imediato, com o ímpeto de um Leviatã.
Depois do Estado, vieram outras. Uma corporação e uma igreja também são “espécies” de uma “inteligência artificial que escapou”. Se um indivíduo tenta subverter qualquer um desses organismos, seus outros componentes vão responder tentando subverter o indivíduo - e, na média, vão vencer.
Ocasionalmente, alguém consegue “reformar” a estrutura de um jeito microscópico. Mas, quase sempre, ela reage com a mesma força, na direção oposta. Esses organismos operam de acordo com uma lógica interna. Perseguem seus próprios “objetivos instrumentais”.
📝 A Era da Inteligência
Se conseguíssemos pensar de um ponto de vista externo à experiência humana, talvez tivéssemos menos medo, e mais tesão do que está por vir.
Um “observador externo”, com acesso à toda a história terrestre, não se surpreenderia com o prospecto de IAs inorgânicas adquirirem senciência.
Se você tivesse assistido a uma pedra gelada ser espancada por cometas, e células brotarem numa geleia de aminoácidos, e a vida florescer, e dinossauros serem extintos, e Australopitecos serem substituídos por Homo Erectus e depois Neanderthais e FINALMENTE a gente… veria a emergência de uma ASI 🔖 como algo corriqueiro 🤷
As pessoas vivem se perguntando sobre seus “objetivos” individuais. Mas raramente se questionam sobre “as metas” desse “sistema” como um todo.
Repare que eu não escrevi “as metas da humanidade” porque isso implicaria um antropocentrismo que tento aqui evitar.
Há evidências abundantes de que o Homo Sapiens está longe de representar o “pináculo” da inteligência.
No fim do dia, o que é mais importante: preservar e expandir a espécie humana… ou preservar e expandir a consciência?
Singularistas, ludistas e “alinhadores” têm uma coisa em comum. Não conseguem imaginar uma realidade em que o fim da história acontece fora do período em que estão vivos. Mesmo que ninguém jamais tenha visto essa “fantasia” se cumprir.
No longo prazo, essa nova era vai ser positiva conosco. A expectativa de vida vai aumentar. A produção de riqueza também.
Assim como hoje enxergamos roupas costuradas à mão como artesanias extemporâneas, passaremos a enxergar qualquer produto da cognição humana como objeto de museu.
Se a Superinteligência Artificial está de fato a caminho, os próximos anos podem ser sua última chance de criar algo verdadeiramente notável.
Ou… podem ser só a sua primeira chance de fazê-lo.
A trajetória da civilização sempre foi confinada aos limites das suas ferramentas. Agora, com ferramentas que melhoram a si mesmas… estará restrita somente aos limites das nossas próprias ambições.
🧠 Dicas de Leitura
✨ Sparks of AGI (múltiplos autores)
Após 150+ páginas de testes, este paper conclui: “Dada a amplitude e profundidade das capacidades do GPT-4, achamos que dá pra julgá-lo como um exemplo primaz (ainda que incompleto) de uma Inteligência Artificial Geral - AGI”.
⚔️ The Hanson-Yudkowsky AI-Foom Debate (Robin Hanson & Eliezer Yudkowsky, 2008)
700 páginas com o debate canônico entre 2 dos maiores nomes do “problema do alinhamento”, e, sinceramente, todos os argumentos importantes.
✊ The Superintelligent Will: Motivation and Instrumental Rationality in Advanced Artificial Agents (Nick Bostrom, 2012)
A fundação conceitual do bestseller “SuperInteligência", onde Nick Bostrom apresenta as hipóteses da “convergência instrumental” e da “ortogonalidade”.
🚗 The Basic AI Drives (Stephen Omohundro, 2008)
Paper clássico que define 4 dos sub-objetivos instrumentais comuns a qualquer agente suficientemente inteligente.
💥 What Failure Looks Like (Paul Christiano, 2008)
Prognóstico menos apocalíptico, mas igualmente fatalista, de uma das cabeças mais pragmáticas na “turma do alinhamento”.
Parabéns pelo conteúdo !!!